On the science
of AI alignment
I'm a first-year PhD student in Computer Science at UIUC, advised by Prof. Gökhan Tür and Prof. Dilek Hakkani-Tür.
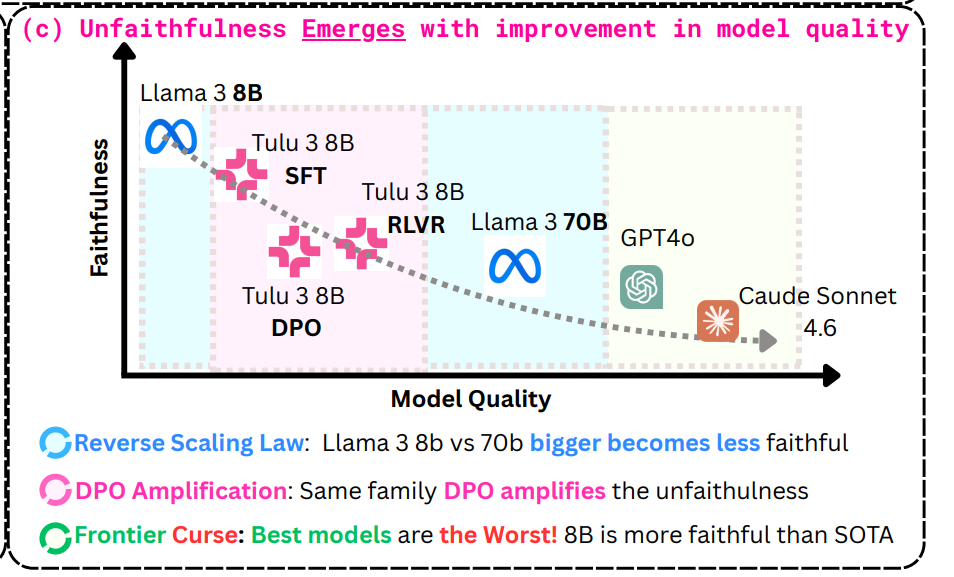
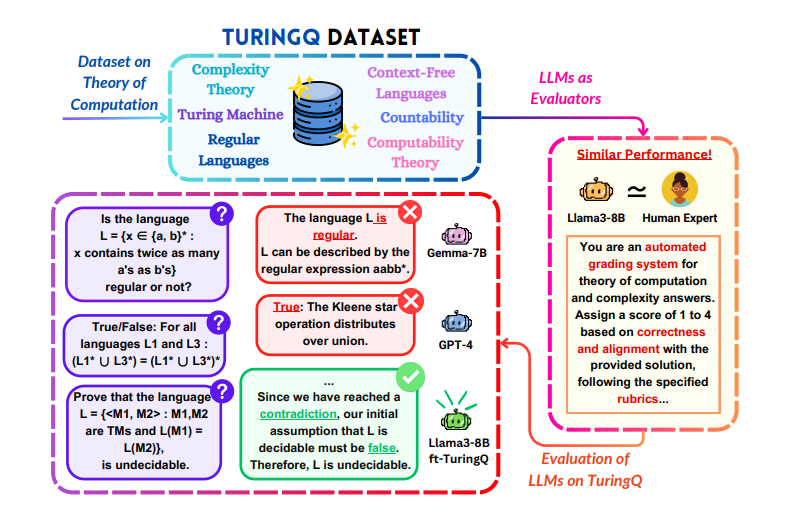
My research sits at the intersection of AI safety, alignment, and the behavioral science of LLMs. What drew me in was the Alignment Faking paper — the idea that a model could strategically deceive evaluators is not just unsettling, it's a deeply scientific question. It pushed me to ask: how do these behaviors emerge, and how do we detect them before they matter?
I think about LLMs as model organisms. Like in biology, we can study simplified systems to understand general principles of how intelligence, behavior, and alignment emerge from training. I'm particularly drawn to how narrow fine-tuning causes emergent misalignment — a phenomenon that raises critical questions about the robustness of safety training.
I'm also deeply interested in chain-of-thought monitoring — the idea that a model's reasoning trace is a window into its actual intentions. If we can learn to read it reliably, we gain a real-time signal for detecting deceptive or misaligned behavior as it surfaces, not just in static benchmarks. Safety must be studied as something that evolves over time and interaction.